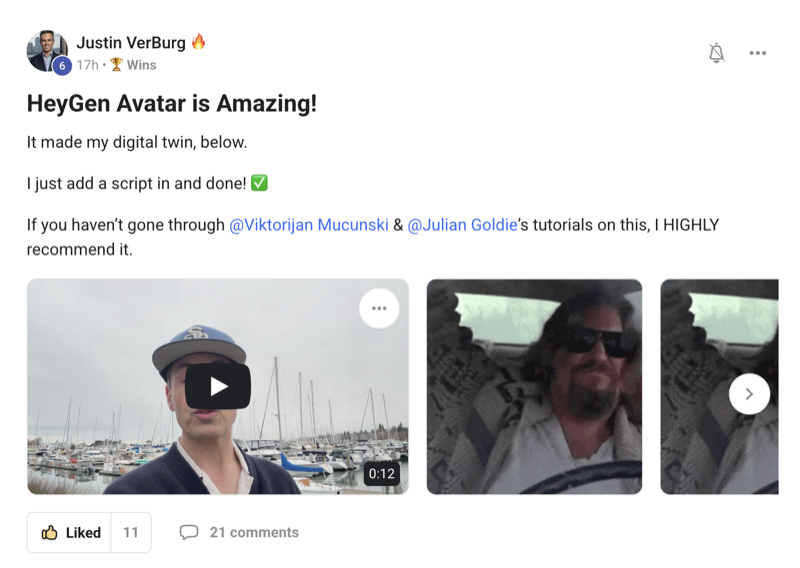
If you're searching for a deepseek v4 tutorial that skips the hype and actually shows you what this model can and can't do — you're in the right place.
DeepSeek launched V4 on the same day OpenAI dropped GPT 5.5.
Bold move.
The Chinese lab is clearly not playing defence anymore.
I sat down, fired up chat.deepseek.com, and put it through its paces.
Video notes + links to the tools 👉
DeepSeek V4 Tutorial: The Two Models You Need To Know
DeepSeek released two models, not one.
Here's the breakdown.
V4 Pro — The Heavy Hitter
- 1.6 trillion total parameters
- 49 billion active per token
- Mixture of experts (MoE) architecture
- 1 million token context window
V4 Flash — The Fast One
- 284 billion total parameters
- 13 billion active per token
- Also MoE, also 1M context
- Faster, cheaper, runs locally on good rigs
Both are fully open source.
Both are available on chat.deepseek.com and platform.deepseek.com.
DeepSeek V4 Tutorial: Where To Use It
Three paths depending on what you want.
Path 1: Web Chat
Open chat.deepseek.com.
Two modes:
- Instant — non-think, fast
- Expert — optional Deep Think reasoning
Path 2: API
Head to platform.deepseek.com.
Three reasoning modes available:
- Non-think — fastest, no CoT
- Think high — step-by-step reasoning
- Think max — up to 384K thinking tokens
Warning: deepseek-chat and deepseek-reasoner endpoints retire after July 24.
Swap to V4 endpoints now.
Path 3: Local
Run it yourself via LM Studio or Hugging Face.
V4 Flash fits on consumer GPUs at a reasonable quant.
V4 Pro needs serious hardware.
How Deep Think Actually Works
This is the feature I was most curious about.
Deep Think is DeepSeek's answer to o3 and Claude's extended thinking.
It uses up to 384K tokens for its reasoning chain on a single problem.
That's more thinking budget than most reasoning models allow for entire contexts.
When to Turn It On
- Maths problems
- Complex coding with edge cases
- Multi-step logic puzzles
- Agentic planning
When to Leave It Off
- Quick lookups
- Simple rewrites
- Factual questions
🔥 Want my DeepSeek Deep Think prompting playbook? Inside the AI Profit Boardroom, I've got a reasoning-model prompts section that covers DeepSeek Deep Think, Claude extended thinking, and GPT 5.5 reasoning — with the exact prompts I use. Plus weekly coaching calls where 3,000+ members compare notes. → Jump into the Boardroom here
My Live Tests
I ran two real-world tasks on DeepSeek V4.
Test 1: Pong Game (Deep Think Mode)
Prompt: "Build a complete Pong game in a single HTML file."
Turned on Deep Think.
Waited.
And waited.
The reasoning chain was long — it really did think hard.
The output worked but the paddle felt laggy.
Generation speed was slower than I'd like.
Verdict: functional, not polished.
Test 2: Landing Page Mockup (Instant Mode)
Prompt: "Build a SaaS landing page with hero, features, and pricing."
Instant mode fired back fast.
Too fast for its own good.
The HTML was clean but the design was V3-era.
Compared to what I get from Claude Opus 4.7 for AI SEO work, there's no contest — Claude wins on UI quality.
Compared to GPT 5.5 Pro, GPT is more modern-looking.
The Benchmarks Tell a Different Story
Here's where it gets spicy.
On benchmarks, DeepSeek V4 is genuinely competitive.
Simple QA Verified
| Model | Score |
|---|---|
| DeepSeek V4 | 57.9 |
| Claude Opus 4.6 Max | 46.2 |
| GPT 5.4 high | 45.3 |
DeepSeek wins factual accuracy clearly.
Codeforces
- 93.5% solve rate
- Ranked 23rd compared to human competitive coders
That 23rd-place ranking against humans is elite territory.
MMLU Pro
- V4 Pro: 87.5
- V4 Flash: 86.2
- Kimi K2.6: close behind
Apex Shortlist
- DeepSeek V4: 90.2%
Architecture — The Tech That Powers It
DeepSeek isn't just scaling up.
They're being clever about it.
Compressed Sparse Attention
4 tokens → 1.
Memory usage drops drastically.
Heavily Compressed Attention
128 tokens → 1 on deeper layers.
This is how they make 1M context affordable.
Manifold Constrained Hyperconnections
4x wider connections between layers.
More signal, less loss.
Muon Optimizer
Dropped AdamW.
Muon optimizer is the new hotness — faster convergence, better final loss.
Training Regime
- Trained on 32 trillion tokens
- Progressive context: 4K → 16K → 64K → 1M
- Context gets extended gradually, not all at once
That progressive training is clever — cheaper than training at 1M from scratch.
Efficiency — The Real Story
Forget benchmarks for a second.
This is the number that actually matters.
Compute Savings
- V4 Pro: 27% of V3.2 compute
- V4 Flash: 10% of V3.2 compute
KV Cache Memory
- V4 Pro: 10% of V3.2
- V4 Flash: 7% of V3.2
That's not incremental.
That's a generational leap in efficiency.
DeepSeek V4 Tutorial: Step-By-Step Setup
Three paths, pick one.
Option A: Web (Easiest)
- Go to chat.deepseek.com
- Log in (free)
- Pick Instant or Expert mode
- If Expert, toggle Deep Think for hard problems
- Chat
Option B: API (Devs)
- Sign up at platform.deepseek.com
- Get an API key
- Pick your reasoning mode (non-think / think high / think max)
- Fire requests — migrate off deepseek-chat/reasoner before July 24
Option C: Local (Privacy/Cost)
- Install LM Studio or Ollama with Hermes
- Search "DeepSeek V4 Flash" in the model library
- Download a quant that fits your VRAM
- Load and chat
Who Should Actually Use DeepSeek V4
Straight talk.
Use It If
- You run high-volume agent workflows (cost matters)
- You need 1M context on a budget
- You want factual accuracy above all
- You want to run a top-tier model locally
Skip It If
- You need polished UI/design output → use Claude
- You need best-in-class creative writing → use GPT 5.5
- You need lightning-fast web search agents → stick with GPT for now
For what it's worth — DeepSeek V4 pairs beautifully with the Kimi K2.6 agent swarm setup I use because you can slot it in as the cheap worker model.
FAQ
Is DeepSeek V4 actually better than GPT 5.5?
Depends on the task.
Benchmarks say yes on factual and coding.
Real-world UI output says no — GPT and Claude still feel more polished.
Is there a free version of DeepSeek V4?
Yes — chat.deepseek.com is free.
V4 Flash is also free to run locally via Hugging Face.
What's Deep Think mode?
It's the optional reasoning mode inside Expert mode on chat.
Uses up to 384K thinking tokens for complex problems.
Can DeepSeek V4 handle a million tokens?
Yes — both Pro and Flash have a 1M context window.
Architecture innovations (compressed sparse attention) make this actually usable, not just a spec sheet claim.
Is DeepSeek V4 open source?
Yes — both Pro and Flash.
Weights available on Hugging Face.
You can fine-tune, redistribute, and self-host.
When do the old endpoints retire?
After July 24 — migrate now.
Related Reading
- GPT 5.5 Pro — the model that launched the same day
- Claude Opus 4.7 for AI SEO — my comparison point for polish
- Kimi K2.6 agent swarms — another open model worth the stack
💸 Want to build DeepSeek V4 agents for a fraction of GPT/Claude costs? Inside the AI Profit Boardroom I teach the exact agent stack I use — DeepSeek for cheap high-volume calls, Claude for polish, GPT for creative. Step-by-step video tutorials, weekly live coaching, and 3,000+ members sharing setups. → Get access here
Learn how I make these videos 👉
Get a FREE AI Course + Community + 1,000 AI Agents 👉
Wrapping Up
DeepSeek V4 is wildly efficient, genuinely clever architecturally, and priced for agents — which makes this deepseek v4 tutorial one you'll want to bookmark before your next build.