How to setup Hermes with Ollama is the question I get most often from operators trying to escape API bills, and this guide walks the exact stack I use to run a free local AI agent that handles 80% of my daily work. After running it for the past few months, I'm convinced this is the cleanest way to ditch token costs without sacrificing meaningful capability.
Most AI agents cost real money to run because API tokens add up fast. A serious daily-use agent on cloud can hit £100-£500 a month easy, and that's before you've added any heavy automation. Local agents fix that, and Hermes plus Ollama is the combo I use to run a free local AI agent that handles the bulk of my daily work without ever touching a paid API.
Why How To Setup Hermes With Ollama Wins
There are three solid reasons to run local rather than cloud for most of your agent workload.
The first is no bills. Local models cost nothing per token, which means you can run them as aggressively as you want without watching the meter.
The second is full privacy. Your data stays on your machine, which matters for client work, sensitive research, and anything you'd rather not send through a third-party API.
The third is always-on availability. No rate limits, no outages, no internet dependency once the install is done.
The catch is that local models aren't quite as smart as the best cloud models. For 80% of work — research, writing, automation, scraping — you won't notice the gap. For the remaining 20% where you need top-tier reasoning, you fall back to cloud.
What You Need
You only need two tools.
The first is Hermes — the AI agent itself, free and open source.
The second is Ollama — the local model runner, also free and open source.
That's it. No paid tier, no subscription, no surprise costs.
How To Setup Hermes With Ollama: The Full Setup
I'll walk you through every step.
Step 1 — Install Ollama
Go to ollama.com and download the installer for Mac, Windows, or Linux. Run the installer.
When it's done, Ollama runs in the background as a local API server. You can verify it's running by visiting http://localhost:11434, which should show "Ollama is running".
Step 2 — Pick your model
Browse Ollama's model library and pick one that fits your hardware. The best free local picks for Hermes are DeepSeek (small and agent-focused), Gemma 4 at around 7GB which is ultra-light, Qwen 3.6 for general-purpose work, and Nemotron 3 Nano Omni at 28GB if you've got the hardware to run Nvidia's new agentic model.
For a free local AI agent on a normal laptop, I'd go with Gemma 4 first.
Step 3 — Download the model
Open terminal and run the install command from the model's Ollama page (e.g. ollama run gemma4). Wait for the download — that's the longest part of the whole setup, taking 5-20 minutes depending on model size and your connection.
Step 4 — Install Hermes
If you haven't already, follow the standard Hermes install on its GitHub. If terminal commands intimidate you, copy the install line and ask Claude Code or Codex to run it for you.
I cover that shortcut in Free Claude Code.
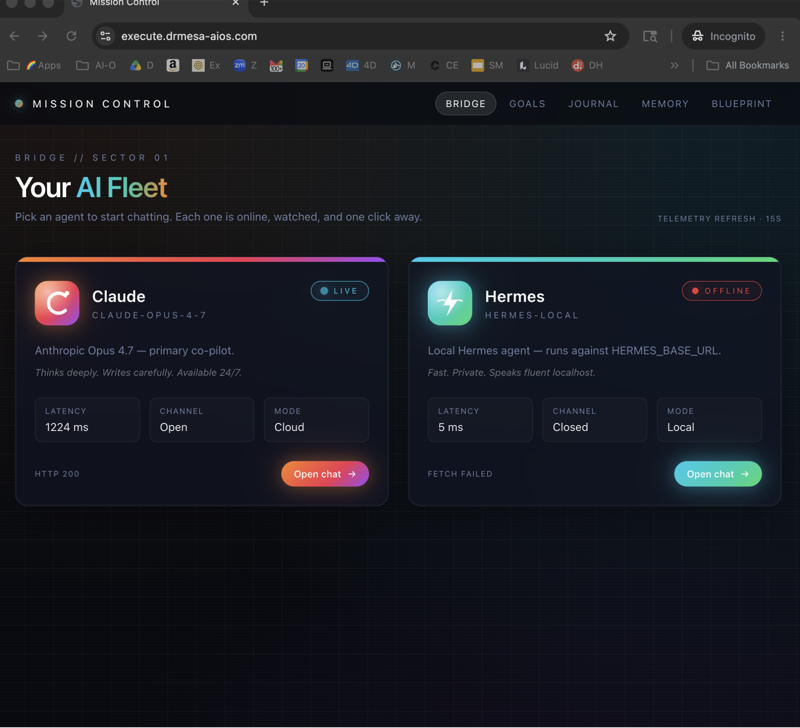
Step 5 — Connect Hermes to Ollama
Open the Hermes config and add your local Ollama as a provider.
Provider: ollama
URL: http://localhost:11434
Model: gemma4
Save and restart Hermes.
Step 6 — Send a message
Open Hermes, pick the Ollama provider, and send "hello — are you working?" If you get a reply, you're done.
🔥 Want my full free local AI agent stack? Inside the AI Profit Boardroom, I share my exact Hermes + Ollama config, recommended models per task, system prompts, and a 2-hour Hermes course. Plus weekly live coaching where you can share your screen and we'll set this up together. 3,000+ members already inside. → Get the stack here
How To Setup Hermes With Ollama: Hardware Requirements
Be honest about what your machine can handle.
For light laptops with 8GB of RAM, stick to small models like Gemma 4 at 7GB. For mid-range machines with 16GB, DeepSeek and Qwen 3.6 work great. For high-end machines with 32GB or more, you can run Nemotron 3 Nano Omni or larger Qwen variants without strain.
I run a Mac Studio so I can throw bigger models at it, but if you're on a normal MacBook or Windows laptop, Gemma 4 is plenty for most workloads.
What You Can Build After Setup Hermes With Ollama
Once Hermes plus Ollama is running, you've got real AI agent capability on your local machine.
The things I use mine for include daily SEO content drafts, email triage, web scraping with the browser skill, research summaries, tweet drafts and captions, and code reviews. Hermes has more than 70 skills, all of which work fine with Ollama models.
For more skill use cases, see Hermes Agent Workspace.
How Free Stays Free
There are two costs to watch out for, even on a "free" stack.
The first is electricity. Running models locally uses your CPU and GPU, which costs pennies per day rather than pounds, but on a laptop it'll heat up and drain battery faster.
The second is storage. Models take disk space — Gemma 4 is 7GB, Nemotron 3 is 28GB — and that adds up if you collect models the way some people collect models.
Otherwise, the stack stays completely free, every day, forever.
Free Cloud Alternatives Within Hermes
If your hardware can't handle local models, Hermes also supports free cloud tiers.
Recommended free cloud combos include the Kimi K2.5 free tier, GLM 5.1, Qwen 3.5 Cloud, and Z AI. These have token limits but they're genuinely usable for most work.
I covered some of these in Kimi K2.6 Agent Swarms.
Comparing Free Local Vs Free Cloud
Quick breakdown of the trade-offs.
| Setup | Cost | Speed | Privacy | Limits |
|---|---|---|---|---|
| Local Ollama | Free | Hardware-dependent | Full | None |
| Free cloud | Free | Fast | None | Token caps |
| Paid cloud | $$$ | Fastest | None | Higher caps |
For a daily-use free local AI agent, Ollama wins. For occasional use, free cloud is fine.
Common Setup Mistakes
There are three things people get wrong when they're starting out.
The first is picking too big a model. Start small with Gemma 4 first and upgrade later if you actually need to.
The second is forgetting to keep Ollama running. Hermes needs Ollama running in the background, and if you close Ollama, Hermes loses access immediately.
The third is running models that don't fit your RAM. If your laptop has 8GB and you try to run a 28GB model, you'll crash. Match the model size to your machine.
The Real Win
I shifted 80% of my Hermes workload to free local Ollama models, and the bills tell the story.
API bills went from £200 a month to under £20. The remaining 20% I run on cloud for tasks that genuinely need bigger models.
That's the win — a free local AI agent that handles most work, with cloud as a backup when needed.
🚀 Want my full Hermes automation system? The AI Profit Boardroom includes a 2-hour Hermes course, daily training drops, and weekly screen-share coaching. Plus a 6-hour OpenClaw course if you want to compare both AI agents. 3,000+ members building real automations. → Join here
FAQ — Free Local AI Agent With Hermes And Ollama
Is Hermes + Ollama really free?
Yes — both tools are free, and local models cost nothing per token.
How much RAM do I need?
8GB minimum for small models like Gemma 4. 16GB is comfortable. 32GB+ if you want the bigger models.
Does it run on Windows and Linux?
Yes. Ollama supports Mac, Windows, and Linux, and Hermes works on all three.
Will my agent work offline?
Yes. Once Ollama and the model are installed, you can run fully offline.
How fast is local vs cloud?
Cloud is generally faster on first response. Local can match it for short responses on smaller models.
Can I run multiple local models at once?
Yes. Ollama can host multiple models, and you can switch between them in Hermes whenever you need.
Is the agent quality good enough for real work?
For research, writing, scraping, and automation — yes. For very complex reasoning, you might still want cloud.
Related Reading
- Hermes Gemma 4 — best beginner local model.
- Hermes DeepSeek — best agentic local model.
- Ollama Hermes — deeper Ollama walkthrough.
📺 Video notes + links to the tools 👉
🎥 Learn how I make these videos 👉
🆓 Get a FREE AI Course + Community + 1,000 AI Agents 👉
That's how to setup Hermes with Ollama for a fully free local AI agent stack — the cleanest way I've found to ditch API bills in 2026.